常见半透明渲染方法
综述类:
半透明渲染新技术摘录
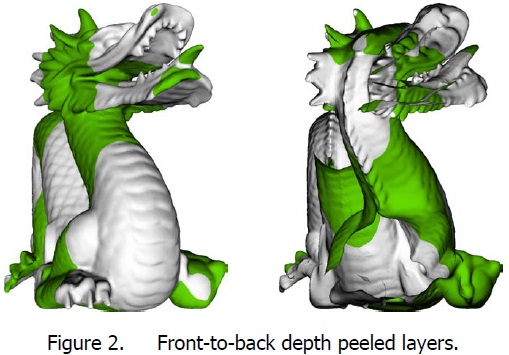
depth peeling的实现和应用
a> A Buffer
[Carpenter 1984]
Achieves order-independent transparency by storing a list of transparent surfaces per pixel. It has long been a staple of off-line rendering and can now be implemented on recent graphics hardware. However, the A-buffer must store all transparent fragments at once, resulting in unpredictable and virtually unbounded storage requirements.
b> Depth Peeling & DualDepthPeeling
科普(自带demo):dual_depth_peeling
以下是算法的关键部分:
Depth peeling [Everitt01] starts by rendering the scene normally with a depth test, which returns the nearest fragments to the eye. In a second pass, the depth buffer from the previous pass is bound to a fragment shader. To avoid read-modify-write hazards, the source and destination depth buffers are swapped every pass (ping ponging). If the fragment depth is less or equal to the associated depth from the previous pass, then this fragment is discarded and the next layer underneath is returned by the depth test.
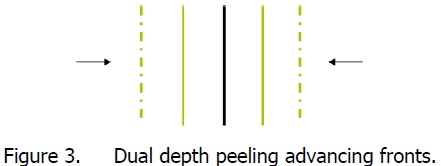
Conceptually, dual depth peeling performs depth peeling in both back-to-front and front-toback directions, peeling one layer from the front and one layer from the back every pass.
c> Billboard sorting & K-Buffer
[游戏行业大部分用的是这种,UE也是]
Renders the objects in sorted order. This is efficient and can be done entirely on the GPU [Sintorn and Assarsson 2008], but is only appropriate for geometry types that don’t overlap in depth. When approximate results are acceptable, a partially sorted list of objects can be rendered with the help of a k-buffer for good results [Bavoil et al. 2007]. 关于K-Buffer再多说几句[需要高版本DX]: Real-time concurrent linked list construction on the GPU:Real-time concurrent linked list construction on the GPU K-Buffer,为了解决A-Buf读写性能而改良了数据结构,就是改了下排序方法:k-buffer
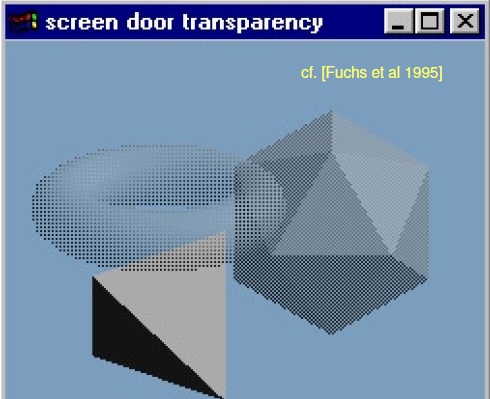
d> Screen-door transparency
[主要用于不支持透明通道的硬件]
Replaces transparent surfaces with a set of pixels that are fully on or off [Fuchs et al. 1985]. The choice of stipple patterns can be optimized so they are more visually pleasing to viewers [Mulder et al. 1998]. The idea of random stipple patterns per polygon has also been long known, and was dubbed cheesy translucency in the original OpenGL “red book” [Neider and Davis 1993]. The sub-pixel variation of screen-door transparency that has been implemented in hardware is alpha-to-coverage, which turns samples on or off to implicitly encode alpha. Because alphato-coverage uses a fixed dithering pattern, multiple layers occlude each other instead of blending correctly, leading to visual artifacts. 一张图搞懂,随机嘛:
e> Stochastic Transparency
[3DMax里用的貌似是这种,有随机点渐变感觉]
StochTransp-slides
StochasticTransparency_I3D2010
核心思想是就是MSAA,搞了个Sub-Pixel,好处就是pass少,速度快,算法时空增长可控,坏处就是重采样。然后需要Alpha Correction一下,也就是再渲染一遍,加上一个矫正因子,看看各个层上的像素的颜色差异,决定矫正的方式。后来又提出了一种叫Depth-based Stochastic Transparency的,就是加上Shadow map继续搞搞搞,思想就是考虑了光照,根据光源的远近改变了下权重。
核心思想都在这张图里:

f> Adaptive Transparency (DX11)
主要是针对光在透明体中的传播,同样一张图搞懂,adaptive_transparency:
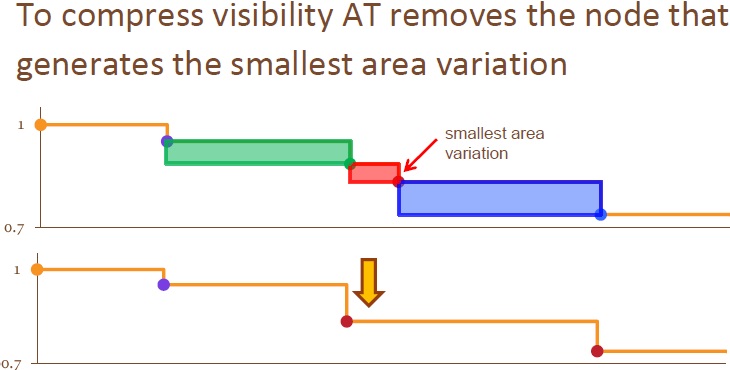
这是近几年的技术了,要彻底搞明白它,还需要研究下AVSM (Adaptive volumetric shadow maps): 原始论文(code,ppt,paper):adaptive-volumetric-shadow-maps 也是一张图(每次约减掉最小面积的三角形,合并顶点):

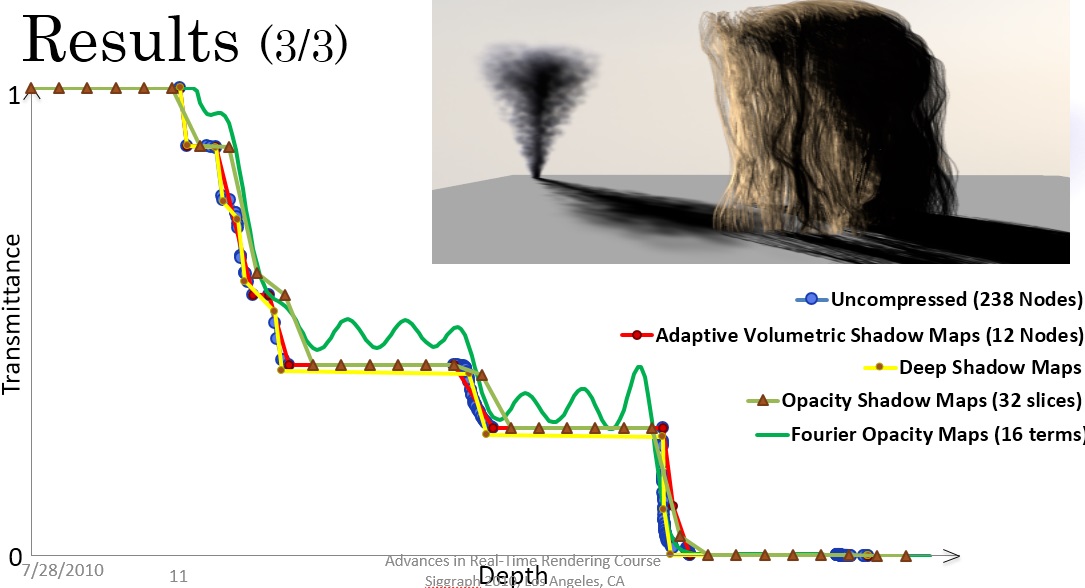
一张图看懂其他的类似算法,这水真是好灌啊(搞了搞曲线拟合,作者画这个图也够走心了):
all> OIT(Order Independent Transparency)
Order-independent_transparency 不排序目前主要以随机类的为主,上面都介绍了。
这两篇大纲性质的PPT,值得看看:
roadToRealTimeOIT-Salvi
order-independent-transparency-opengl
其他
2010的sg,重点看Real-Time Order Independent Transparency and Indirect Illumination using Direct3D 11这篇,详细阐述了LinkList的创建方法。
这篇PPT有很多可圈可点的,下面给出的是一个OIT的流程,第二步明显可以和延迟渲染进行结合。

13~18页讲述了如何创建链表。方法需要对纹理的随机写,两块buf,这个性质导致dx9没法做。另外写buf时候记得加锁,轻度的spin-lock就行。

ATI’s Mecha Demo:效果速度俱佳,但实现起来有难度,需要最新的硬件。用链表存储片段。

下面这个PPT详细介绍了DX11中的UAV,采用这种链式结构改良了不少算法,上次研究UE4的FFT水插件也用到了UAV,具体是否UE4抽象出一层,有待继续研究:oit-and-indirect-illumination-using-dx11-linked-lists
最后
这张网越撒越大,真担心有点收不住,还好技术都是大同小异,关键是思想(近几年图形发展很多都是基于链表的改良,感觉就是炒炒现饭)。之所以OIT研究这么多,原因是不需要排序,且可和延迟渲染相结合,前途无量。
另外,TressFX 的半透毛发渲染是基于 PPLL(per pixel linked list)的,能支持 DX11 的显卡都可以用。 PPLL的主要问题点在于:
- 需要一张较大的 A buffer 储存所有的半透像素(包括重叠的)。
- 在 NV fermi 架构系列上有加大 cache miss 导致效率低下。