Motion Matching Synthesis
PFNN
2016 # Conv Autoencoder
# Learning Motion Manifolds with Convolutional Autoencoders1
# A Deep Learning Framework for Character Motion Synthesis and Editing2
将编辑看作三维空间中的目标优化问题,将该问题转化为低维latent space上的优化问题,能保证结果依旧自然,不会出现人工编辑带有的artifacts。使用了骨骼卷积这一方式,对后续的动作生成以及重定向都产生了比较深远的影响。
2017 # PFNN - Single Global Phase
# Phase-Functioned Neural Networks for Character Control3
回顾上一篇,为了解决ambiguity,作者增加了一个模块专门提取输入high level的frequency和duration,为路径添加约束,但这种做法只适合离线,因为实时的control下,这些参数都是随时可能发生变化。另一个思路则是从运动本身下手,从当前周期的状态求得下一个时间点状态,同时,ambiguity的问题也同样得到了解决,因为给人增加了所处状态的约束信息。
实现原理:
- 训练多个参数集合 $ \alpha_0,\alpha_1,\alpha_2,\alpha_3 … $
- 引入phase function提供相位系数
- 根据系数,使用Catmull-Rom对参数lerp
- 将参数赋予网络,求解
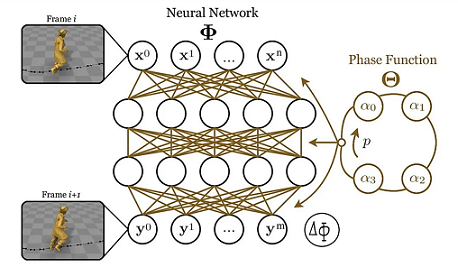
作者在PhD毕业后去了育碧,PFNN这篇工作在游戏界有很大的影响力,但也有明显的缺陷:只能用于walk,run这样的有phase的动作,对于其他没有phase的动作,PFNN就不work了。
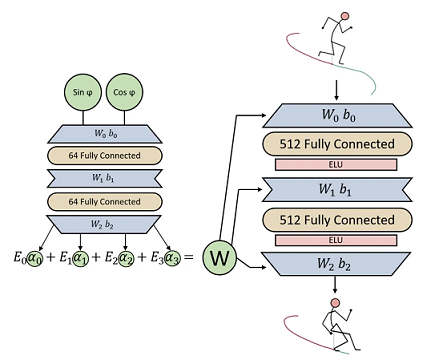
2018 # MANN - MoE(Mixture Of Experts)
# Mode-Adaptive Neural Networks for Quadruped Motion Control4
四足动物的运动模式比人复杂的多,因此不能用单一相位建模。
希望计算机自己学习四足动物运动的模式,即用专家系统(MoE)来代替相位系统,以指导神经网络:
2019 # Multiple Global Phases
# Neural State Machine for Character-Scene Interactions5
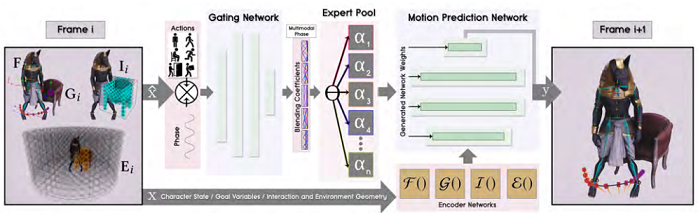
环境千变万化,要生成足量的数据分析环境是工作量非常大。在这篇文章中,作者也先只关注了有限个交互情况上,如弯腰过墙,坐在桌子上,搬东西,坐在椅子上,开门。
人的行为可以通过mocap捕捉,环境信息呢?以椅子为例,作者从ShapeNet中选取了大量各种各样的椅子,然后计算人与椅子交互时接触的关节点(手、臀部),再通过IK重新计算motion的信息,这样,一方面不仅不需要采集环境信息,还可以通过这种方式获得大量多样的数据,这是文章的重要贡献之一。
2020 # Contact-based Local Phases
# Local Motion Phases for Learning Multi-Contact Character Movements6
这篇文章想解决的是打篮球的问题:
- 相位系统
由于任务会有大量快速且复杂的碰撞过程,如果用单一相位函数驱动,肯定是不合理的。
把几个核心过程取出来,左脚运动,右脚运动,左手和球互动,右手和球互动,球与地面接触。
以此建立5个小的周期系统,即 Local:

- 输入控制
训练时,计算出来的运动信号都是复杂且细腻,而测试时,键鼠/手柄难以达到这种细腻程度。
Local Motion Phase 采取了一个非常巧妙的方式:用生成网络完成伪造,让信号重构更精细。
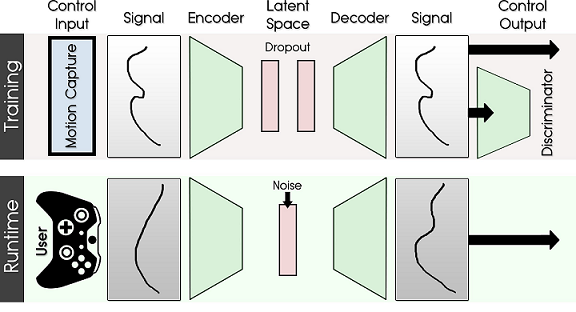
训练(Training)时,让生成网络学会重构信号。因此,先从动捕数据中抽象出控制信号 $ x $,比如运动轨迹,是否持球等作为训练数据。设计的生成网络可以做到重构这些数据,并且创建一个代表动作的隐变量空间 $ Z $,作为中间过渡。完成训练后,生成网络的Encoder可以把任何控制信号 $ x $ 压缩成动作隐变量 $ z $,而生成网络的Decoder可以把任何动作隐变量变成逼真的动作信号 $ x_{reconstruct} $。
运行(Inference)时,再用手柄或者键鼠生成粗糙的控制信号 $ x $(运动轨迹,是否持球等)。通过训练好的重构网络,就可以重构成和真的动捕轨迹一样。具体来讲,生成网络的Encoder将这个粗糙信号压缩成动作隐变量 $ z $,加上一些Noise,就得到了丰富多变的运动隐变量 $ z_n $。最后通过训练好的Decoder,把粗糙、加噪的隐变量 $ z_n $ 解码成真实有效的控制信号 $ x_n $。控制信号通过神经网络后,就得到接近真实的动作组合 $ y $ 了。
2022 # PCA Heuristic Local Phases
# DeepPhase: Periodic Autoencoders for Learning Motion Phase Manifolds
如何表达非周期的函数?很显然:FFT
这也是DeepPhase核心的思路:
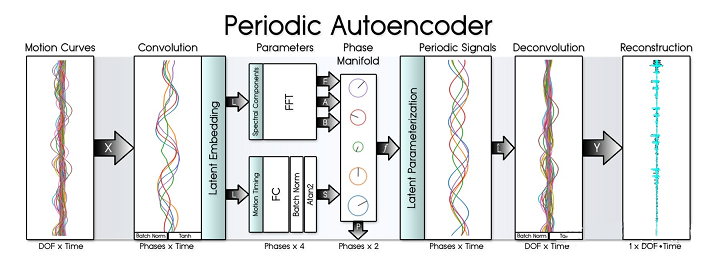
小结
PFNN之后,Daniel Holden的师弟Sebastian Starke,He Zhang等延续了PFNN
PFNN # 奠定了相位系统的基础架构,有能力建模全局周期的动作行为。
MANN # 复杂运动模式相位并不单一,引入专家系统来代替相位系统,以指导神经网络。
Local Motion Phase # 弥补了PFNN的重大短板,有局部周期性动作,LMP就可以生成。
DeepPhase # 完成了相位系统的广义拓宽,将这个思想应用到所有动作中去,包括非周期动作。
这些工作都非常出彩,一定程度上奠定了动画AI这个全新领域。这一系列工作都延续PFNN的思想,使用了MANN中提出的MoE网络架构,来尽可能的提升动画效果。当然,这一系列的工作也不是没有问题,就是做的越来越复杂以至于很难复用,同时使用AI始终面临着OOD(Out of Distribution)问题,也就是在动画中一旦神经网络的输入是没有遇到过的场景,神经网络可能会输出一些奇怪的状态,完全不符合动画要求,相反,Motion Matching和状态机因为都是使用原始动画,则没有这个问题。
论文及源码:https://github.com/sebastianstarke/AI4Animation
综述视频:https://www.youtube.com/watch?v=wNqpSk4FhSw
其他文章:
《动作生成的智能之路》789
《角色动画:现状与趋势》10
《Data-Driven Character Motion Synthesis》11
LMM
Learning = Compression
Daniel Holden 在 Ubisoft 提出了 Learned Motion Matching12,将 Motion Matching 思路与 AI 结合,目的是大幅度降低动画占用的内存,并尽可能限制AI泛化,使输出动画都映射到动画库中,基本和 Motion Matching 效果一致,是将 Motion Matching 应用到游戏中值得考虑的技术。
网络定义
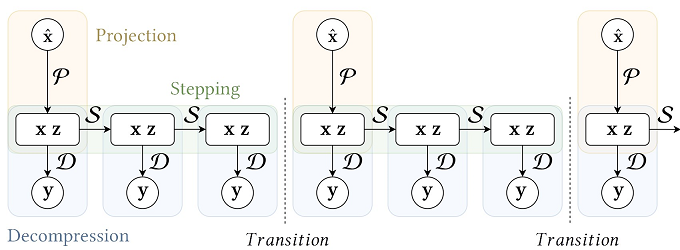
D # 用神经网络来代替数据库,进而达到降低内存。
C # 由 Y 作为输入提供额外隐变量 Z (Latent),以提高 D 的准确性。
P # 根据输入返回 X,Z,代替特征值在数据库中的搜索过程。
S # 根据前帧 X,Z 预测后帧的 X,Z,代替序列往后拨动,避免 ambiguity。
源码分析 13
数据变量
float feature_weight_foot_position; // 足部 位置 权重
float feature_weight_foot_velocity; // 足部 速度 权重
float feature_weight_hip_velocity; // 髋部 速度 权重
float feature_weight_trajectory_positions; // 轨迹 位置 权重
float feature_weight_trajectory_directions; // 轨迹 速度 权重
// 每个变量组成:关节数 * 3D向量
// local (相较于父节点的坐标,ROOT节点除外)
array1d<vec3> curr_bone_positions; // 每个关节的局部位置 size: 23 * 3
array1d<vec3> curr_bone_velocities; // 每个关节的局部速度 size: 23 * 3
array1d<quat> curr_bone_rotations; // 每个关节的局部四元数 size: 23 * 4
array1d<vec3> curr_bone_angular_velocities; // 用四元数的轴角表示速度 size: 23 * 3
// global (世界坐标,ROOT节点还是原来的坐标)
array1d<vec3> global_bone_positions; // 每个关节的全局位置 size: 23 * 3
array1d<vec3> global_bone_velocities; // 每个关节的全局速度 size: 23 * 3
array1d<quat> global_bone_rotations; // 每个关节的全局四元数 size: 23 * 4
array1d<vec3> global_bone_angular_velocities;// 用四元数的轴角表示速度 size: 23 * 3
数据文件
character.bin // 角色数据
simulation_run.bin // 动画数据
simulation_walk.bin // 动画数据
database.bin // Pose及原始特征,即 X Y
latent.bin // Z
features.bin // X 产生于界面的 Rebuild
decompressor.bin // D network 的参数
stepper.bin // S network 的参数
projector.bin // P network 的参数
Train # Decompressor
# train_decompressor.py
decompressor.bin + latent.bin ← database.bin + features.bin
# 其他产物
decompressor_X.png
decompressor_Z.png
decompressor_Ygnd.bvh // 原始数据
decompressor_Ytil.bvh // 拟合数据
<.bvh # Motion Capture 文件,可用Blender打开>
类比为一个生成网络:C 为 Encode,D 为 Decoder
Latent # 稀疏性(sparsity) & 平滑性(smoothness)
Pose # 平滑性(smoothness) [位置 & 速度 & 加速度]
Train_Decompressor(Feature, Pose, θC, θD):
Pose_Global = Forward_Kinematics(Pose) # 生成全局 pose
Latent ← C([Pose Pose_Global]; θC) # Compressor 生成 Latent 变量
Pose_D ← D([Feature Z]T; θD) # Decompressor 生成重建的 pose
Pose_D_Global ← Forward_Kinematics(Pose_D) # 生成全局重建的 pose
# 计算 Loss
L_lreg ← w_lreg * square(Latent) # 平方
L_sreg ← w_sreg * abs(Latent) # 绝对值之和
L_vreg ← w_vreg * abs(△Latent/dt) # 变化速度的绝对值之和
L_loc ← w_loc * abs(Pose - Pose_D) # 包括 joint 4个参数 root 的速度2个参数
L_chr ← w_chr * abs(Pose_Global - Pose_D_Global)
L_lvel ← w_lvel * abs(△Pose/dt + △Pose_D/dt)
L_cvel ← w_cvel * abs(△Pose_Global/dt + △Pose_D_Global/dt)
# loss 的总和
Loss ← SUM(L_lreg + ... + L_cvel)
# 更新参数
θC, θD ← RAdam(θC θD, ∇Í∗ Loss)
Train # Projector
# train_projector.py
projector.bin ← database.bin + features.bin + latent.bin
# 其他产物
projector_X.png
projector_Z.png
对 Feature 随机选定一帧 Feature_Rand 进行加噪(模拟输入),输入 Projector 网络,生成 Feature_P 和 Latent_P 尽可能和最近邻的 Feature_K 和 Latent_K 吻合(方便实现映射到现有 Pose)
Train_Projector(Feature_Rand, Feature, Latent, θP):
# 生成一个噪声(均匀噪声 & 高斯噪声)
N_U, N_G ← U(0, 1), N(0, 1)
# 添加噪声 (方差 * 均匀噪声 * 高斯噪声)
Feature_Noise ← Feature_Rand + (Feature_std * N_U * N_G)
# 寻找最近邻的 Feature
Feature_K, Latent_K ← Nearest(Feature_Noise, [Feature Latent])
# Projector 生成 Feature 和 Latent
Feature_P, Latent_P ← P(Feature_Noise; θP)
# 计算 Loss
L_xval ← w_1 * abs(Feature_K - Feature_P) # Feature 真实值匹配
L_zval ← w_2 * abs(Latent_K - Latent_P) # Latent 真实值匹配
L_dist ← w_3 * abs(dist(Feature_Noise, Feature_K)
- dist(Feature_Noise, Feature_P)) # 防止噪声太大的选项
# loss 的总和
Loss ← SUM(L_xval + L_zval + L_dist)
# 更新参数
θP ← RAdam(θP; Loss)
Train # Stepper
# train_stepper.py
stepper.bin ← database.bin + features.bin + latent.bin
# 其他产物
stepper_X.png
stepper_Z.png
Stepper 生成 s 步,使生成的 Feature 和 Latent 尽可能与真实值吻合(平滑性[位置 & 速度])
这里保存的是变化量,且与网络帧数(dt)相关,使用时需要注意一下。
Train_Stepper(Feature_In, Latent_In, s, θS):
# 备份
Feature_S[0], Latent_S[0] ← Feature_In[0], Latent_In[0]
# Stepper 生成 s步
for i ← 1 to s
# Stepper 生成变化量
Feature_delta, Latent_delta ← S([Feature_In[i-1], Latent_In[i-1]]; θS)
# 更新
Feature_S[i], Latent_S[i] ← [Feature_S[i-1], Latent_S[i-1]] + [Feature_delta, Latent_delta]
#计算loss
L_xval ← w_1 * abs(Feature_In - Feature_S)
L_zval ← w_2 * abs(Latent_In- Latent_S)
L_xvel ← w_3 * abs(△Feature_In / dt - △Feature_S / dt)
L_zvel ← w_4 * abs(△Latent_In/ dt - △Latent_S/ dt)
# loss 的总和
Loss ← SUM(L_xval + ... + L_zvel)
# 更新参数
θS ← RAdam(θS; Loss)
Evaluate # Decompressor
- 输入 Features 和 Latent
- 运行 Decompressor,输出 Pose
void decompressor_evaluate(
slice1d<vec3> bone_positions, // 输出骨架 positions 信息
slice1d<vec3> bone_velocities, // 输出骨架 velocities 信息
slice1d<quat> bone_rotations, // 输出骨架 rotations信息
slice1d<vec3> bone_angular_velocities, // 输出骨架 angular_velocities信息
slice1d<bool> bone_contacts, // 双脚离地了,病毒就关闭了,聪明的智商又占领高地了
nnet_evaluation& evaluation, // Decompressor 结构
const slice1d<float> features, // Decompressor 输入的 feature
const slice1d<float> latent, // Decompressor 输入的 latent
const vec3 root_position, // 上一时刻 root position (目标位置)
const quat root_rotation, // 上一时刻 root rotation (目标位置)
const nnet& nn, // Decompressor 参数
const float dt = 1.0f / 60.0f)
{
slice1d<float> input_layer = evaluation.layers.front();
slice1d<float> output_layer = evaluation.layers.back();
// 设置网络的输入 features + latent
for (int i = 0; i < features.size; i++) {
input_layer(i) = features(i);
}
for (int i = 0; i < latent.size; i++) {
input_layer(features.size + i) = latent(i);
}
// Decompressor 生成 pose
nnet_evaluate(evaluation, nn);
// 提取输出骨架 positions 信息
int offset = 0;
for (int i = 0; i < bone_positions.size - 1; i++) {
bone_positions(i + 1) = vec3(
output_layer(offset+i*3+0),
output_layer(offset+i*3+1),
output_layer(offset+i*3+2));
}
offset += (bone_positions.size - 1) * 3;
// 提取输出骨架 rotations 信息,并转换为 4元数形式
for (int i = 0; i < bone_rotations.size - 1; i++) {
bone_rotations(i + 1) = quat_from_xform_xy(
vec3(output_layer(offset+i*6+0),
output_layer(offset+i*6+2),
output_layer(offset+i*6+4)),
vec3(output_layer(offset+i*6+1),
output_layer(offset+i*6+3),
output_layer(offset+i*6+5)));
}
offset += (bone_rotations.size - 1) * 6;
// 提取输出骨架 velocities 信息
for (int i = 0; i < bone_velocities.size - 1; i++) {
bone_velocities(i + 1) = vec3(
output_layer(offset+i*3+0),
output_layer(offset+i*3+1),
output_layer(offset+i*3+2));
}
offset += (bone_velocities.size - 1) * 3;
// 提取输出骨架 angular velocities 信息,并转换为 4元数形式
for (int i = 0; i < bone_angular_velocities.size - 1; i++) {
bone_angular_velocities(i + 1) = vec3(
output_layer(offset+i*3+0),
output_layer(offset+i*3+1),
output_layer(offset+i*3+2));
}
offset += (bone_angular_velocities.size - 1) * 3;
// 提取输出 root 位置的 velocities 和 angular velocity 信息,并转换为世界坐标
// 即两个速度信息代表着目标所在的位置
vec3 root_velocity = quat_mul_vec3(root_rotation, vec3(
output_layer(offset+0),
output_layer(offset+1),
output_layer(offset+2)));
vec3 root_angular_velocity = quat_mul_vec3(root_rotation, vec3(
output_layer(offset+3),
output_layer(offset+4),
output_layer(offset+5)));
offset += 6;
// 通过 root 的 velocity 信息更新 root_position
bone_positions(0) = dt * root_velocity + root_position;
bone_velocities(0) = root_velocity;
// 通过 root 的 angular velocity 信息更新 bone_rotations
bone_rotations(0) = quat_mul(
quat_from_scaled_angle_axis(root_angular_velocity * dt),
root_rotation);
bone_angular_velocities(0) = root_angular_velocity;
// 提取双脚状态 输出 > 1/2 认为接触地面
// 输出 < 1/2 认为未接触地面
if (bone_contacts.data != nullptr) {
bone_contacts(0) = output_layer(offset+0) > 0.5f;
bone_contacts(1) = output_layer(offset+1) > 0.5f;
}
offset += 2;
// Check we got everything!
assert(offset == nn.output_mean.size);
}
Evaluate # Projector
- 标准化 Feature 数据,生成 Projector 的输入
- 运行 Projector,得到新 Feature
- 计算更新前后距离,差距不大则输出原 Feature
其中 transition_cost = 0,且调用没赋值,应是作者失误
void projector_evaluate(
bool& transition, // 是否需要转移(Projector 匹配结果和现阶段比较)
float& best_cost, // 判断未标准化feature之间差距
// trns_dist_squared 判断标准化feature之间差距
slice1d<float> proj_features, // Projector 生成 feature
slice1d<float> proj_latent, // Projector 生成 latent
nnet_evaluation& evaluation, // Projector 结构
const slice1d<float> query, // 当前 feature 值 (非标准化的值)
const slice1d<float> features_offset, // 当前 feature 值的偏移
const slice1d<float> features_scale, // 当前 feature 值的放大倍数
const slice1d<float> curr_features, // 当前 feature 值 (标准化的值)
const nnet& nn, // Projector 参数
const float transition_cost = 0.0f)
{
slice1d<float> input_layer = evaluation.layers.front();
slice1d<float> output_layer = evaluation.layers.back();
// 标准化 生成网络的输入
for (int i = 0; i < query.size; i++){
input_layer(i) = (query(i) - features_offset(i)) / features_scale(i);
}
// 根据 Input_layer 跑 Projector 网络
nnet_evaluate(evaluation, nn);
// 拷出 Projector 网络输出的
for (int i = 0; i < proj_features.size; i++){
proj_features(i) = output_layer(i);
}
for (int i = 0; i < proj_latent.size; i++){
proj_latent(i) = output_layer(proj_features.size + i);
}
// 计算更新之后的 feature 和更新前的 feature 之间的距离(标准化对比)
best_cost = 0.0f;
for (int i = 0; i < proj_features.size; i++){
best_cost += squaref(query(i) - proj_features(i));
}
best_cost = sqrtf(best_cost);
// 计算更新之后的 feature 和更新前的 feature 之间的距离(非标准化对比)
float trns_dist_squared = 0.0f;
for (int i = 0; i < proj_features.size; i++){
trns_dist_squared += squaref(curr_features(i) - proj_features(i));
}
// 差距过大,则使用 P 输出的结果(这里用哪个差距都一样,都得转)
if (trns_dist_squared > squaref(transition_cost)){
// transition and add the transition cost
transition = true;
best_cost += transition_cost;
}
else {
// Don't transition and use current features as-is
transition = false;
for (int i = 0; i < proj_features.size; i++){
proj_features(i) = curr_features(i);
}
// Re-compute the projection cost
best_cost = 0.0f;
for (int i = 0; i < curr_features.size; i++) {
best_cost += squaref(query(i) - curr_features(i));
}
best_cost = sqrtf(best_cost);
}
}
Evaluate # Stepper
- 运行 Stepper
- 更新 Features 和 Latent(输出其变化量)
void stepper_evaluate(
slice1d<float> features, // 输入的 features 并且在函数中更新
slice1d<float> latent, // 输入的 latent 并且在函数中更新
nnet_evaluation& evaluation, // Stepper 结构
const nnet& nn, // Stepper 参数
const float dt = 1.0f / 60.0f)
{
slice1d<float> input_layer = evaluation.layers.front();
slice1d<float> output_layer = evaluation.layers.back();
// 设置 input 为 features 和 latents
for (int i = 0; i < features.size; i++) {
input_layer(i) = features(i);
}
for (int i = 0; i < latent.size; i++) {
input_layer(features.size + i) = latent(i);
}
// Stepper 生成输出 features 和 latent 的变化量
nnet_evaluate(evaluation, nn);
// 更新 features 和 latents
for (int i = 0; i < features.size; i++){
features(i) += dt * output_layer(i);
}
for (int i = 0; i < latent.size; i++) {
latent(i) += dt * output_layer(features.size + i);
}
}
实践
技术选型
管线流程
<未完待续…16>